Using pre-trained language models to resolve textual and semantic merge conflicts (experience paper)
Abstract
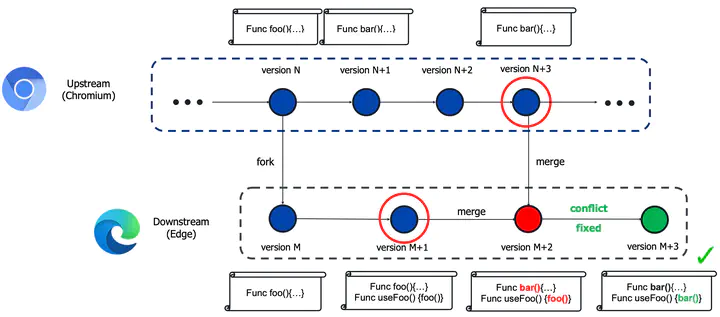
Program merging is standard practice when developers integrate their individual changes to a common code base. When the merge algorithm fails, this is called a merge conflict. The conflict either manifests as a textual merge conflict where the merge fails to pro- duce code, or as a semantic merge conflict where the merged code results in compiler errors or broken tests. Resolving these conflicts for large code projects is expensive because it requires developers to manually identify the sources of conflicts and correct them. In this paper, we explore the feasibility of automatically repairing merge conflicts (both textual and semantic) using k-shot learning with pre-trained large neural language models (LM) such as GPT-3. One of the challenges in leveraging such language models is fitting the examples and the queries within a small prompt (2048 tokens). We evaluate LMs and k-shot learning for both textual and semantic merge conflicts for Microsoft Edge. Our results are mixed. On one-hand, LMs provide the state-of-the-art (SOTA) performance on semantic merge conflict resolution for Edge compared to earlier symbolic approaches; on the other hand, LMs do not yet obviate the benefits of special purpose domain-specific languages (DSL) for restricted patterns for program synthesis.
Jialu Zhang
Tenure-Track Assistant Professor
My academic work is in software engineering and programming education. It focuses on methods and tools that help students and developers understand, test, and improve programs.